为什么 MySQL 选择使用 B+ 树作为索引结构?
为什么 MySQL 选择使用 B+ 树作为索引结构?
等价于对比其他数据结构,首先要明确一点的是MySQL选择数据结构一定是要优先适合磁盘存储的,而不是内存存储。尽最大可能减少磁盘io是最重要的选择依据,其次还要支持高效查询,因此我们考虑以下常见的数据结构
普通链表
这个很明显不用考虑,无法高效的查询(查询是O(n)复杂度),也不支持范围查询等操作。
二叉搜索树
为了使查询时间尽量减少,我们可以考虑二分查找,对于树而言,普通二叉搜索树(BST),AVL树和红黑树都支持二分查找,时间复杂度上,BST极端情况会退化成普通链表,也就是不平衡,导致查询时间增加为O(n);
而AVL树因为有了严格平衡的策略,使得查询时间始终为O(logn),但正因为严格平衡策略,导致插入数据就极有可能触发旋转操作,最坏情况下需要 2 次旋转;
红黑树不像AVL树严格平衡(每个节点的左右子树高度差的绝对值不超过1),只需要尽量平衡,因此插入数据大部分情况只需要进行染色,无需旋转,且旋转最坏情况和AVL树保持一致,最多2次,因此效率优于AVL树,这也是Java TreeMap、C++ STL map等选择红黑树作为底层数据结构的原因。
Q:回归到MySQL,那么既然红黑树查询,插入都很优秀,那为什么不选它呢?原因在于树高导致的磁盘I/O次数
A:假设有 1000 万条数据(千万级)
红黑树高度约 = log₂(1e7) ≈ 23
这意味着:
- 查一次索引,需要从根走到叶子 ≈ 23 层
- 每层一个指针跳转(可能对应一次磁盘随机 I/O)
- 最坏 23 次磁盘随机读取
实际磁盘随机 I/O:毫秒级
数据库无法接受这么多随机 I/O。因此二叉树不是合适的选择
另外,需要说明的是:既然需要这么多I/O,那为什么java map还要用它呢?答案就在开头介绍的day02,对于磁盘而言随机I/O是毫秒级,但是对于内存而言,随机访问所需要的时间是纳秒级!!!,时间成本几乎为零,这点I/O成本 nobody care!!!
多叉树
既然二叉树树高太大、导致磁盘 I/O 次数不可接受,那么自然想到要使用多叉树,通过提升分叉数来降低树高。于是就有了 B 树和 B+ 树。
B 树(B-Tree)
特点:
- 多叉平衡树,一个节点可以存大量 key
- 树高大幅降低(几层即可覆盖千万数据)
- 非叶子节点和叶子节点都存储数据
缺点:
- 范围查询不方便,因为数据分布在各层节点,需要不停跳节点,多次随机 I/O
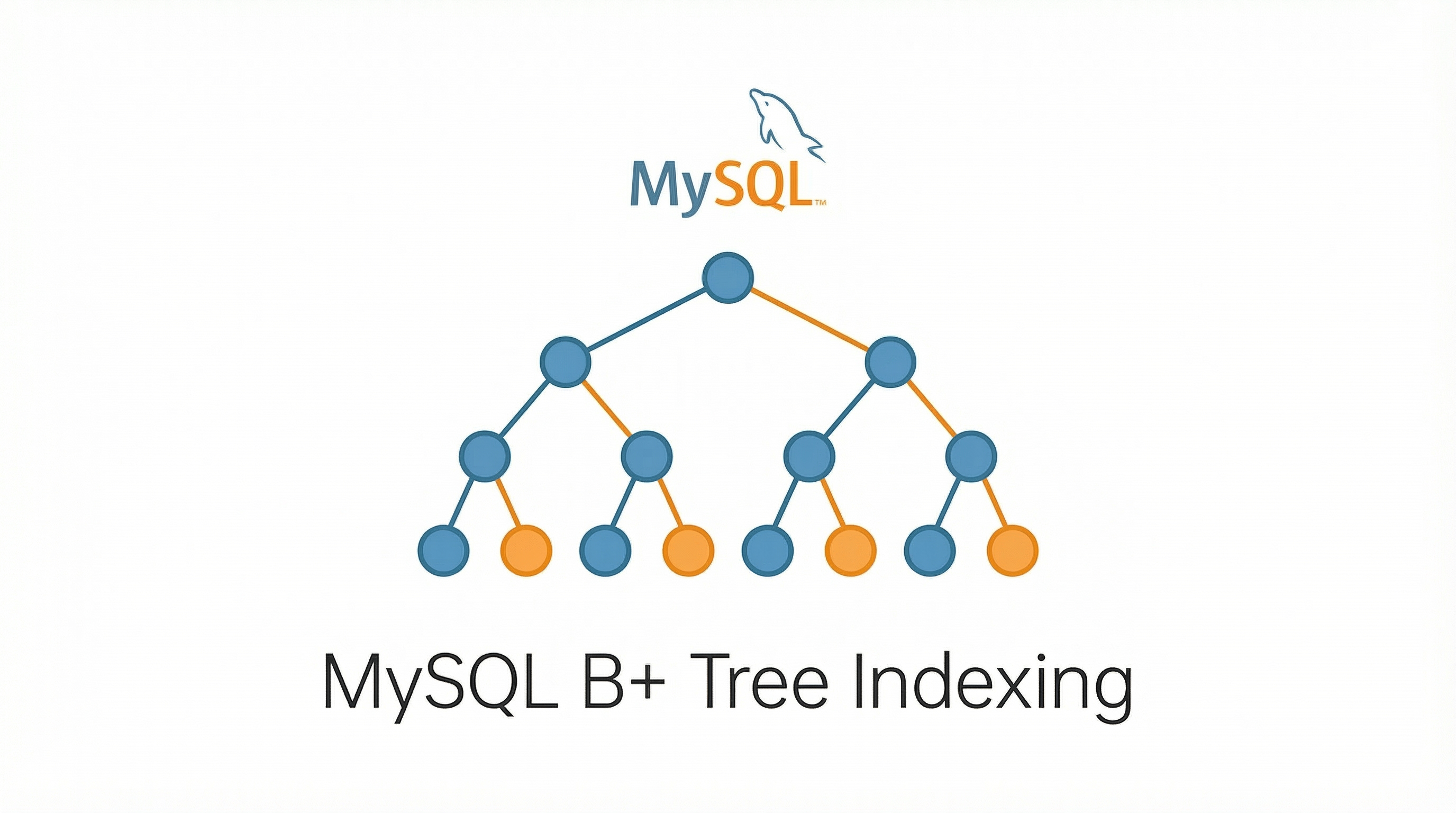
B+ 树
B+ 树是专为磁盘结构优化的:
- 所有数据都在叶子节点
内部节点只存索引,页能容纳更多 key → 分叉更多 → 树更矮 → I/O 更少。 - 叶子节点之间有顺序链表
只读叶子链表即可完成范围查询、排序查询,无需随机 I/O。 - 一个节点对应一个磁盘页(默认16KB)
读一个节点就读一个页,I/O 次数更可控。
结果:
- 千万级数据树高约 3~4 层(3层树高可容纳2000w级别数据)
- 查一次只需 3~4 次磁盘 I/O(并且大部分情况下根节点和中间节点都在缓存内,实际可能只需1次磁盘I/O,大幅优于红黑树可能需要 20 多次随机 I/O)
结论
B+ 树树高低、I/O 少、范围查询强,是最适合磁盘存储结构的索引树,因此 MySQL 最终选择 B+ 树。
埋个todo:跳表将在redis相关问题中对比